Develop
Locust can be run locally but it truely shines when run on a serverless provider. When trying out or developing Locust jobs, it is simpler to run Locust locally to avoid extraneous issues related to cloud providers. In this guide, we'll get up and running locally with Locust.
Create a job
The locust-cli provides a generator that steps through creating the basic components of a job:
locust generate
Example prompt
For more in depth explaination what can be configured in a job, check the API docs.
Validate the job
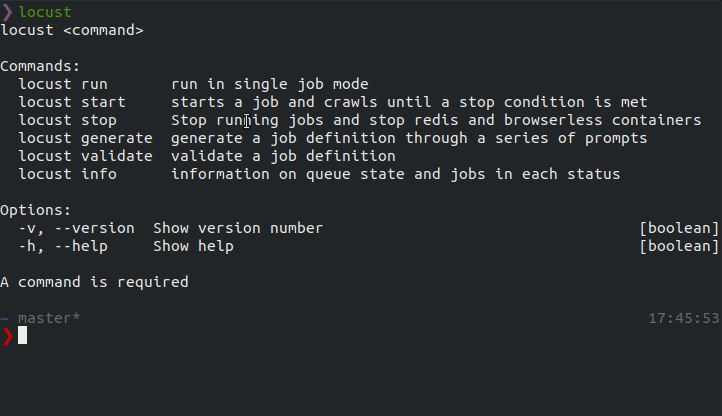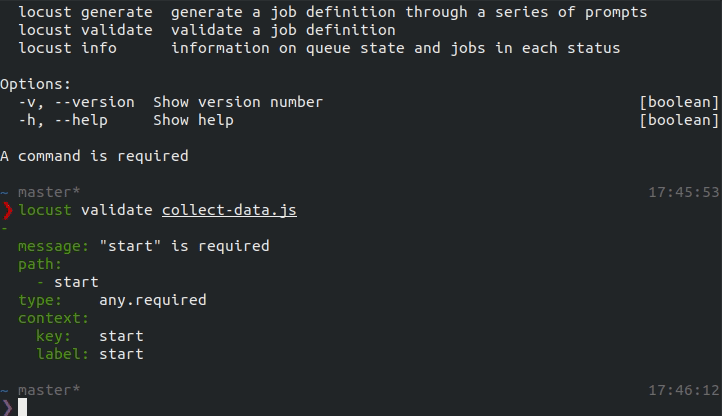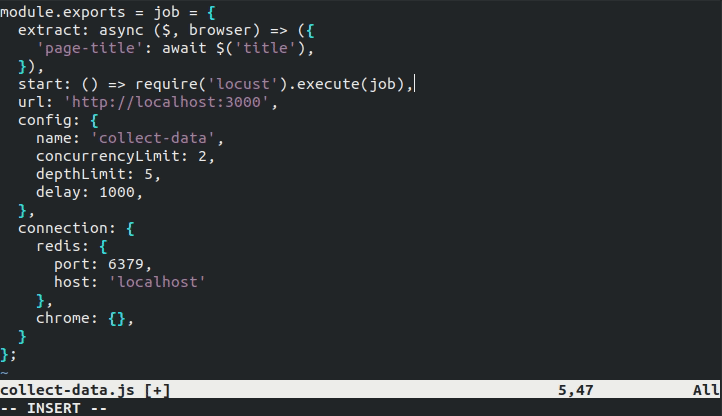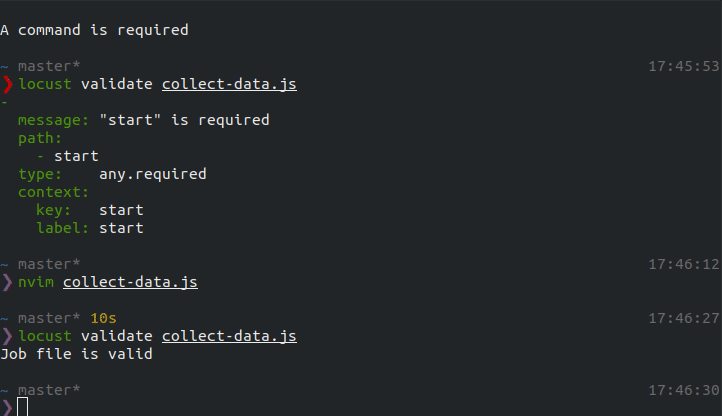
Before running the job, validate that that is conforms to the spec:
locust validate collect-data.js
Example output
Test the job
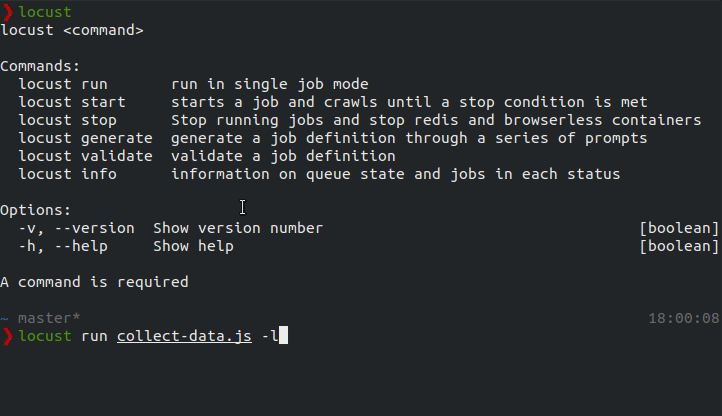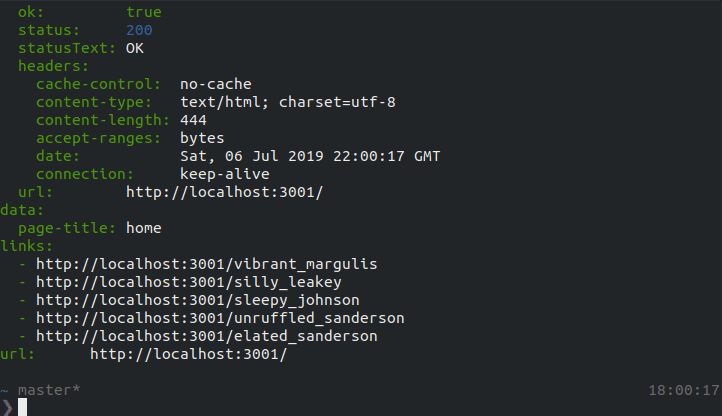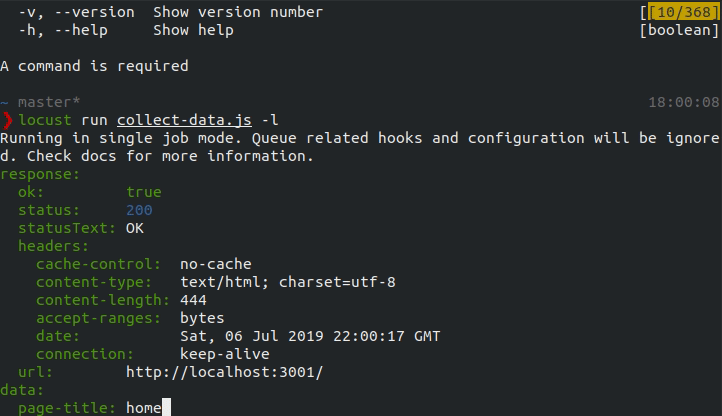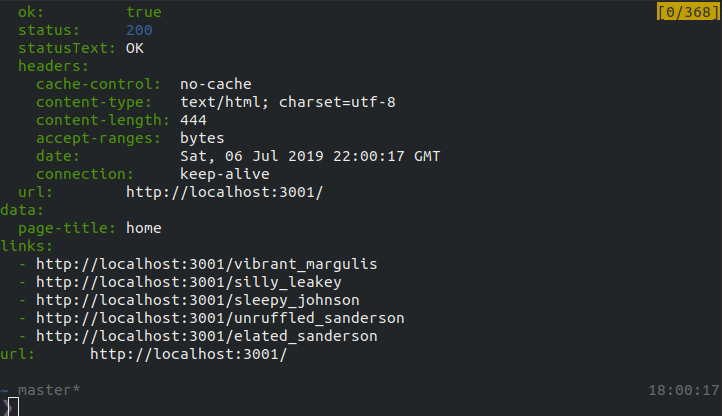
First try running the job in limited-mode to confirm that any data or link extraction is working as expected. While running in limited-mode, Locust will only run against the entrypoint url.
locust run collect-data.js -l
In the above response, any fields defined in the extract function and and links one the page should be included which confirms that the job works as expected.
Note
Lifecycle hooks, queue configuration, and connection configuration are ignored in limited-mode
Run the job
Setup
In order to run Locust in standard-mode, a Redis and Chrome instance must be running. The easiest way to start these is with the CLI.
Note
Docker and Docker Compose must be installed before running this command.
locust start -b
Example output
This is a shortcut to start a Docker Compose file. Alternately, the redis and chrome containers can be started with ad-hoc commands.
Persistence
The CLI will save results to a timestamped JSON file (e.g. results-2019-06-29-20-50-22.json) after a run for debug purposes.
Example output
[
{
"data": {
"title": "home"
},
"links": [
"http://localhost:3001/vibrant_margulis",
"http://localhost:3001/silly_leakey",
"http://localhost:3001/sleepy_johnson",
"http://localhost:3001/unruffled_sanderson",
"http://localhost:3001/elated_sanderson"
],
"url": "http://localhost:3001/"
}
]
When running outside the CLI, locust does persist any data. In order to retain data collected during a run, an after hook can be added to the job file:
...
after: (jobResult) => client.query('INSERT INTO products(name, photo_url) VALUES ($1, $2)'),
...
Run
Now that the job been proven to work on a single page, run the job in standard-mode to confirm lifecycle hooks and queue configuration work as expected.
locust start collect-data.js
Example output
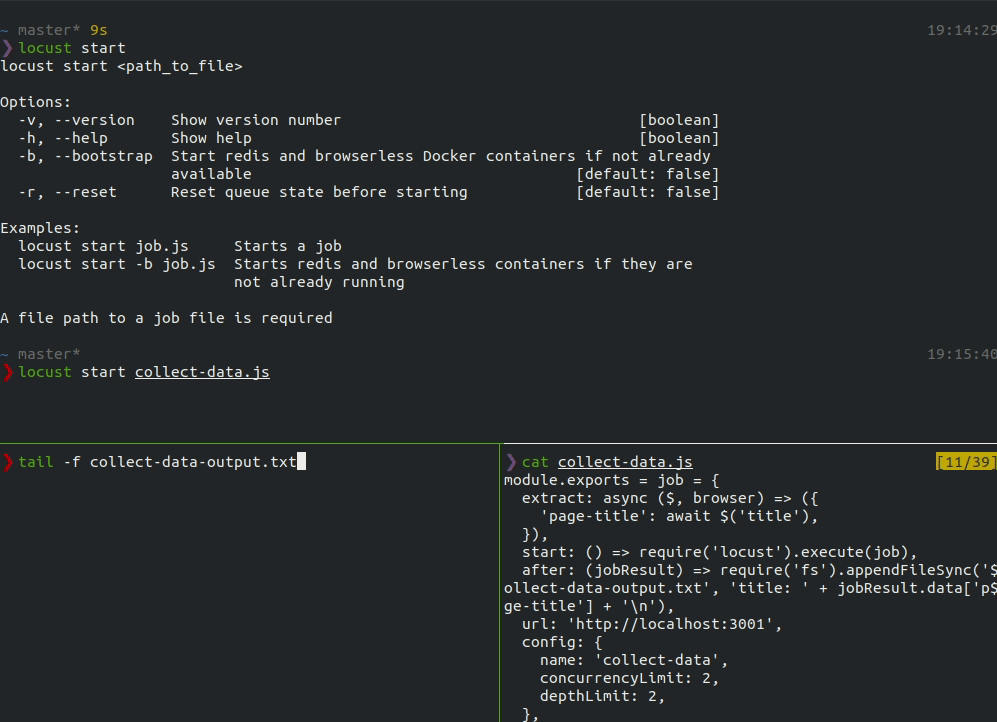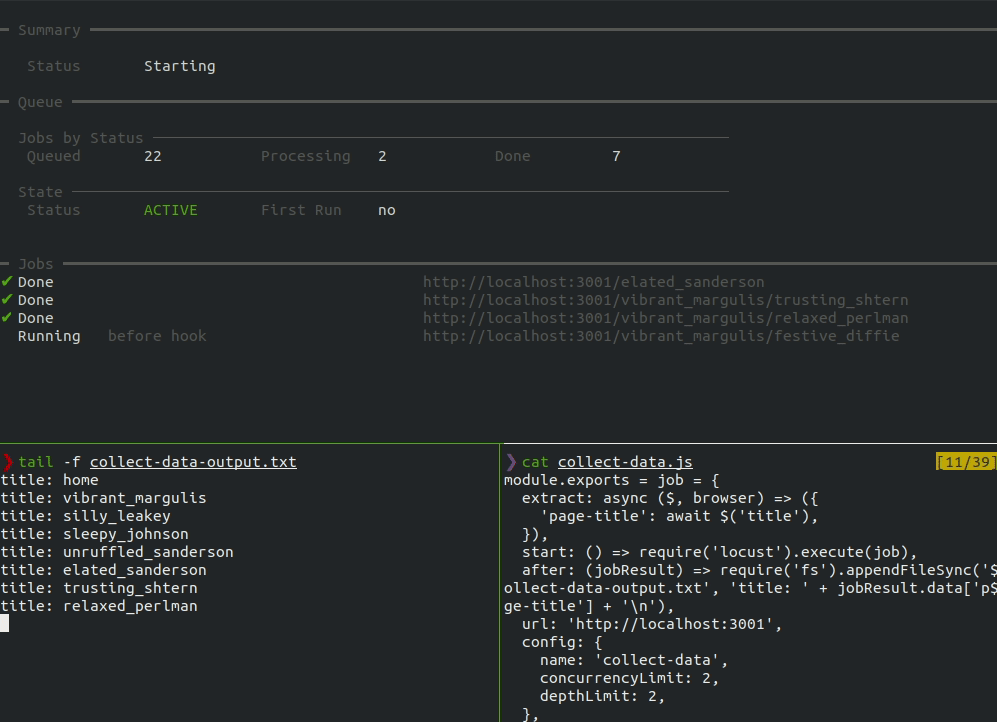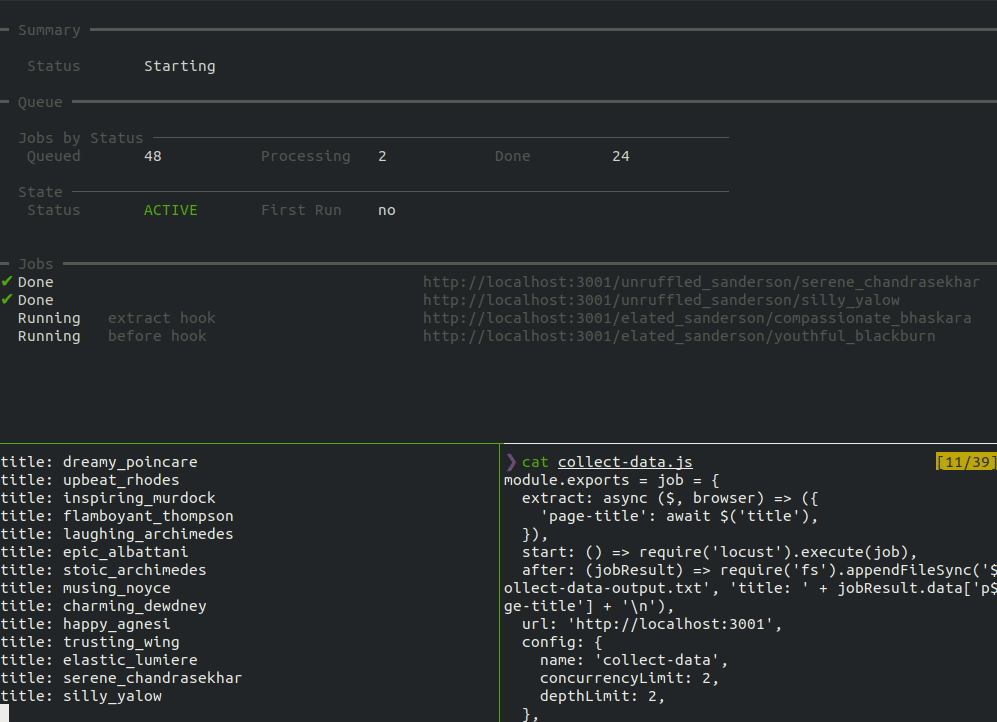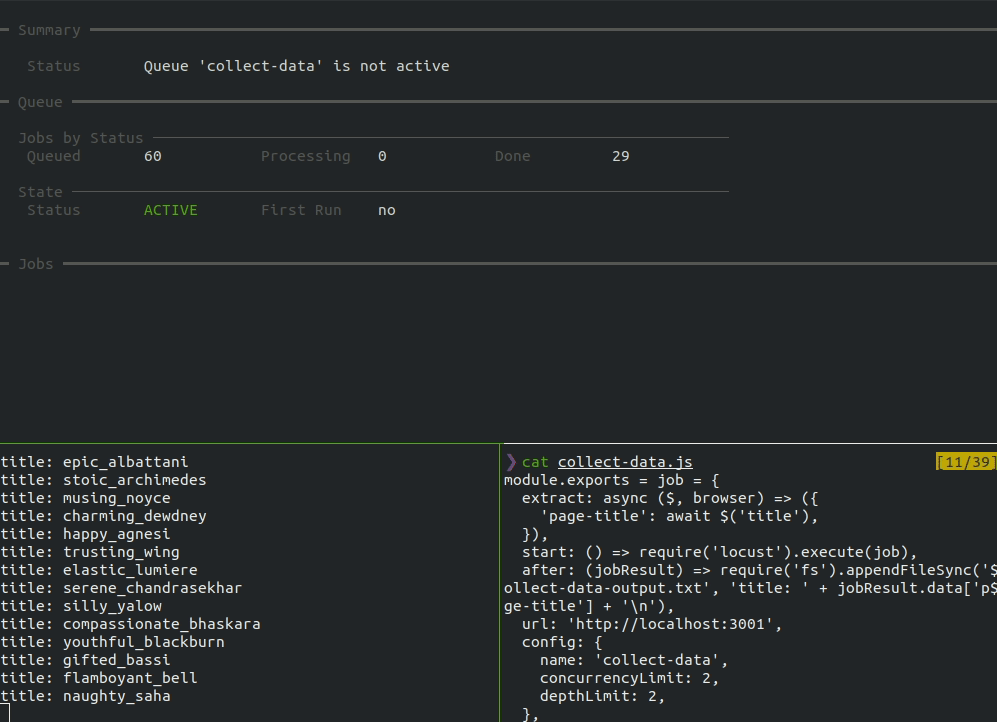
When the start command is run, the dashboard shows the overall status, the number of jobs in each status, the status of the queue, and a running list of jobs.
Note
The start lifecycle hook is ignored when running with the cli in either standard-mode or limited-mode.